Retrieval Augmented Generation
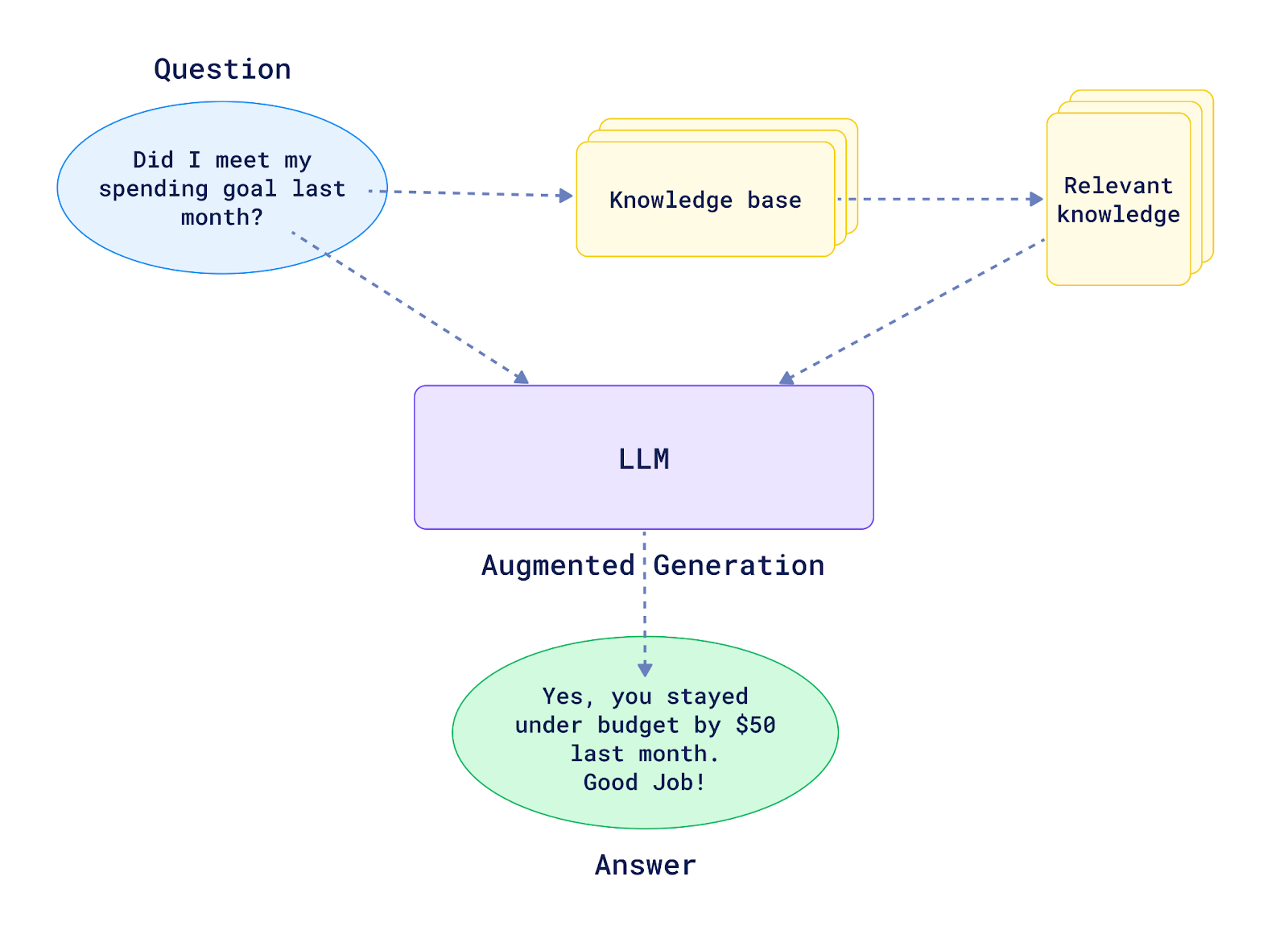
The Retriever
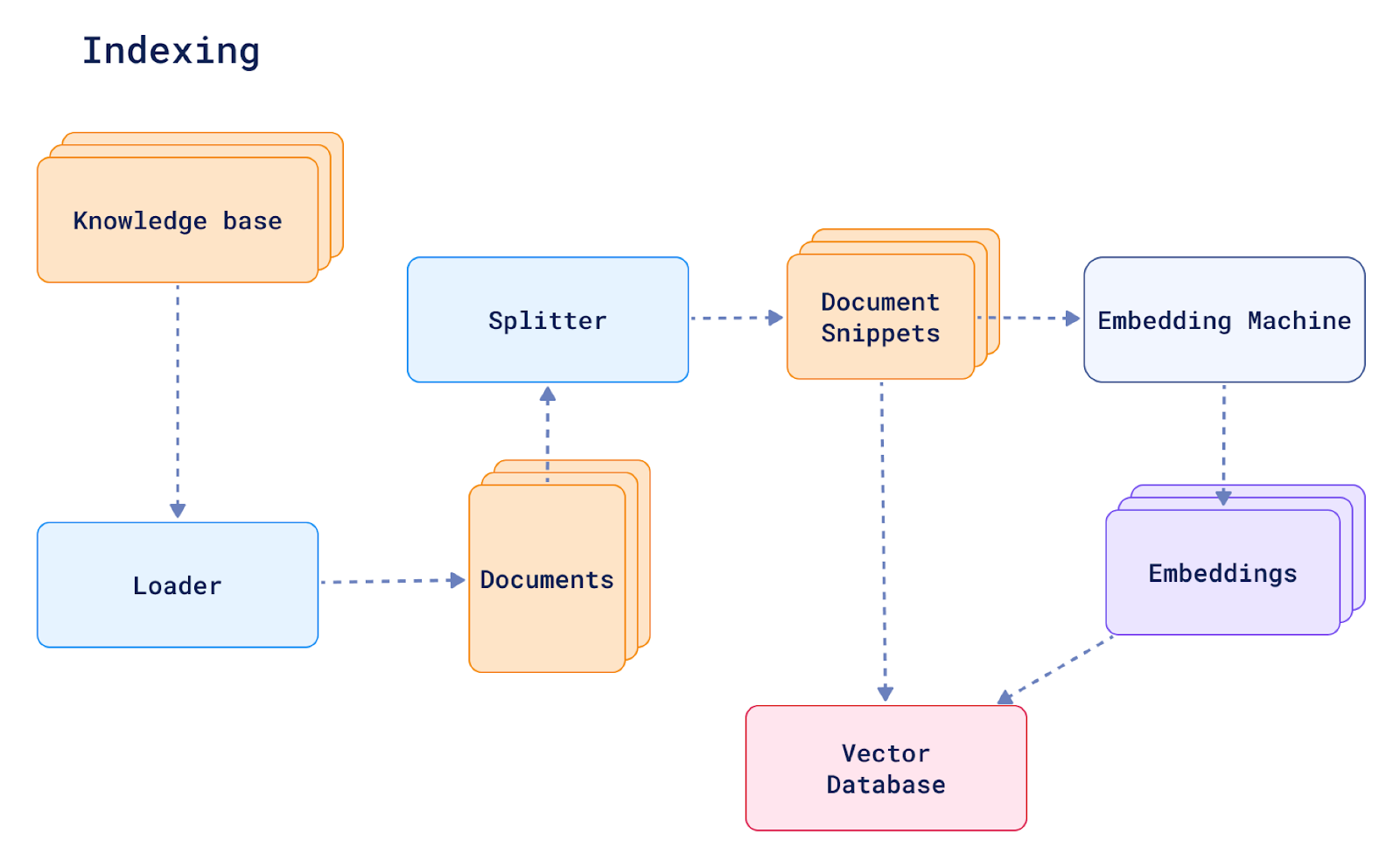
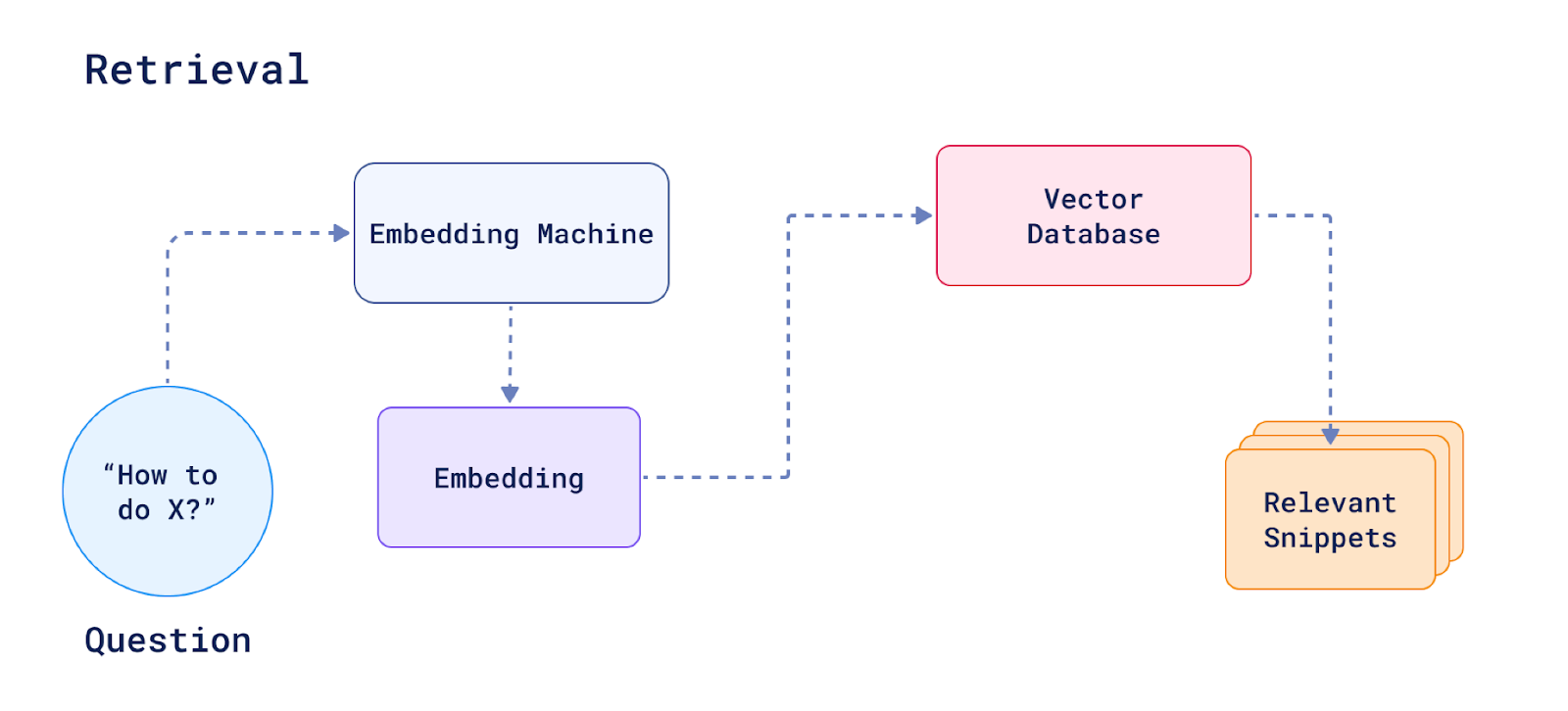
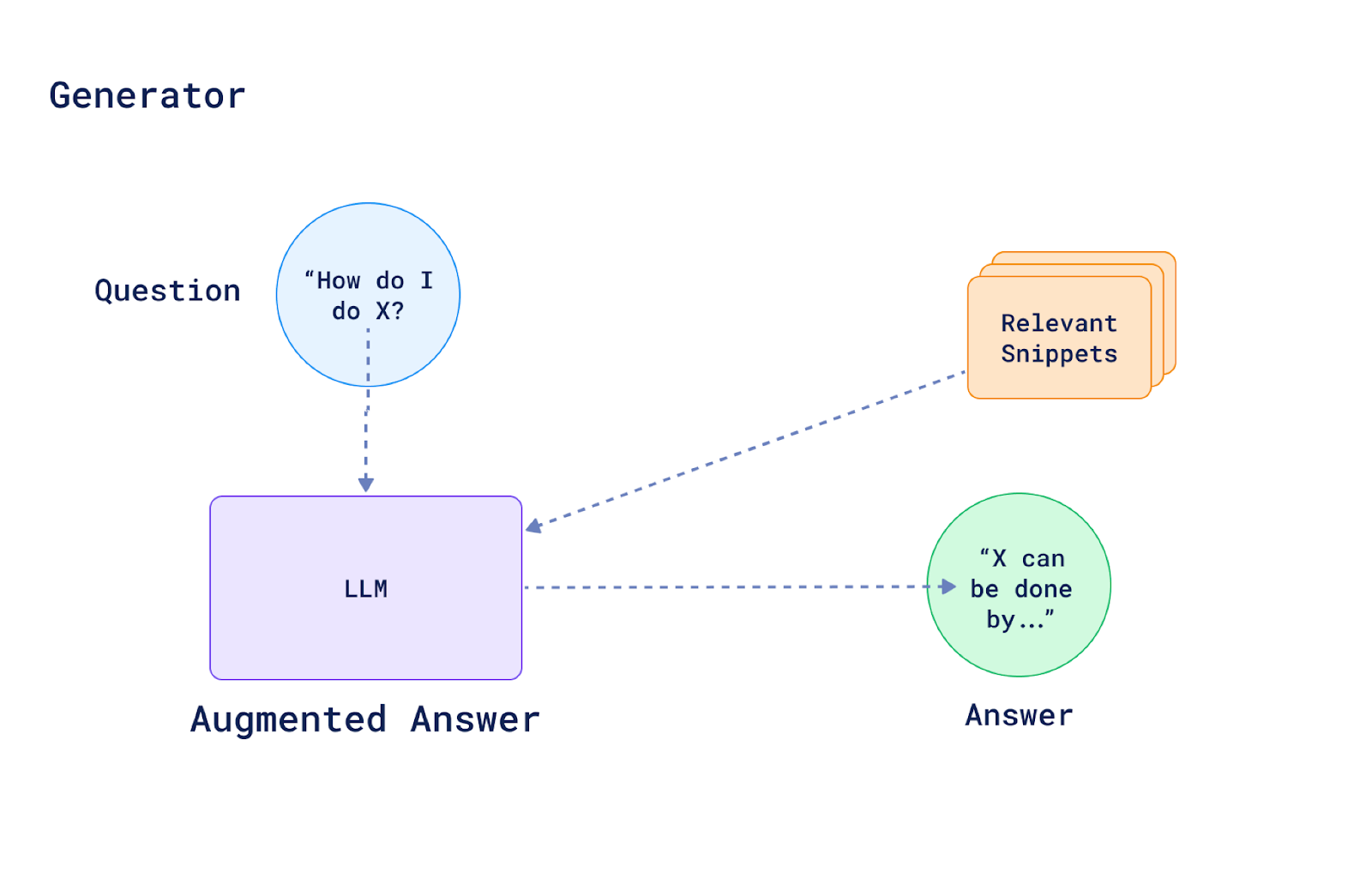
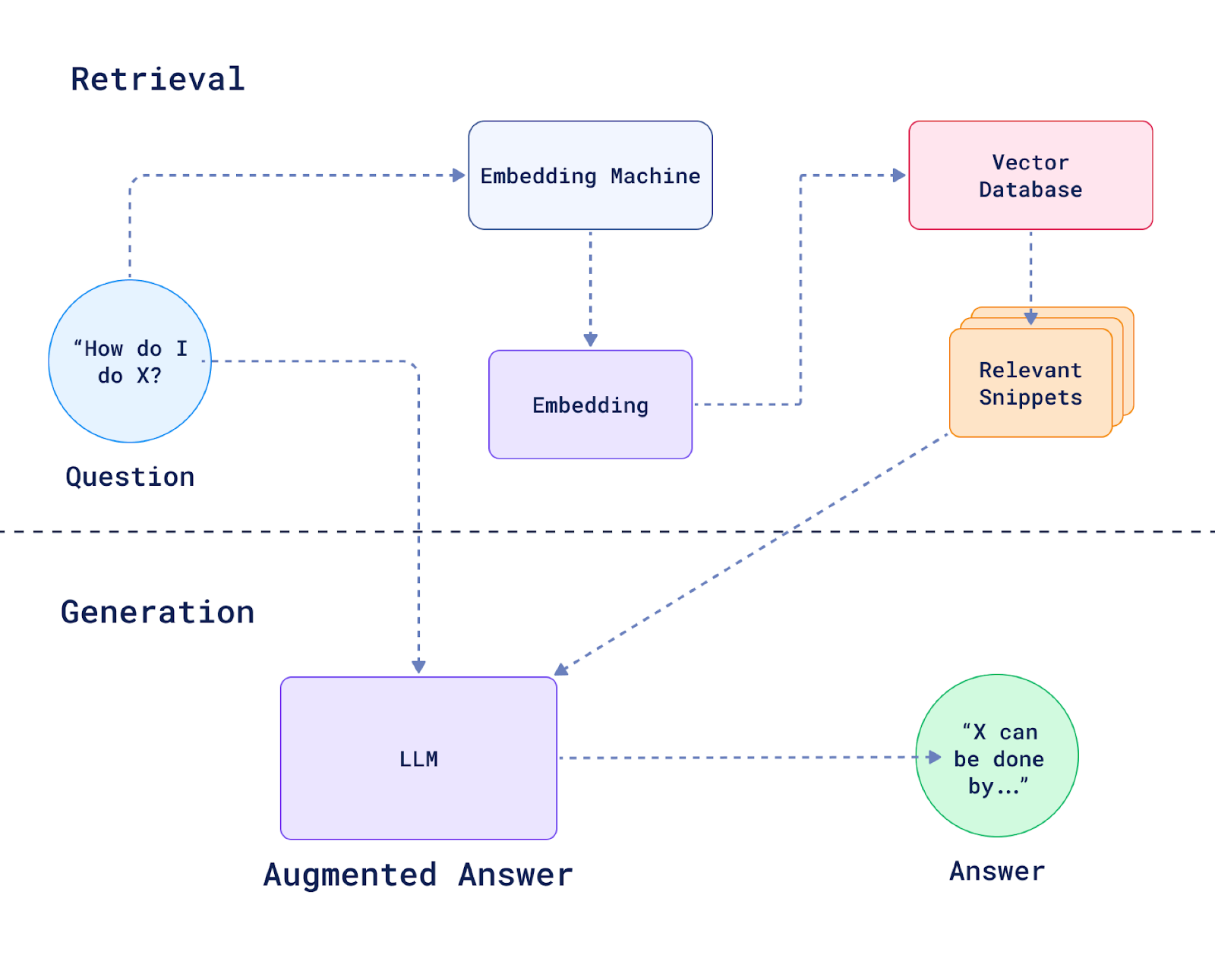

some of the snippets retrieved from the vector database are not always relevant or of good quality, e.g. the contents pages of a book
Solution?
Add another LLM of course!
Reranker
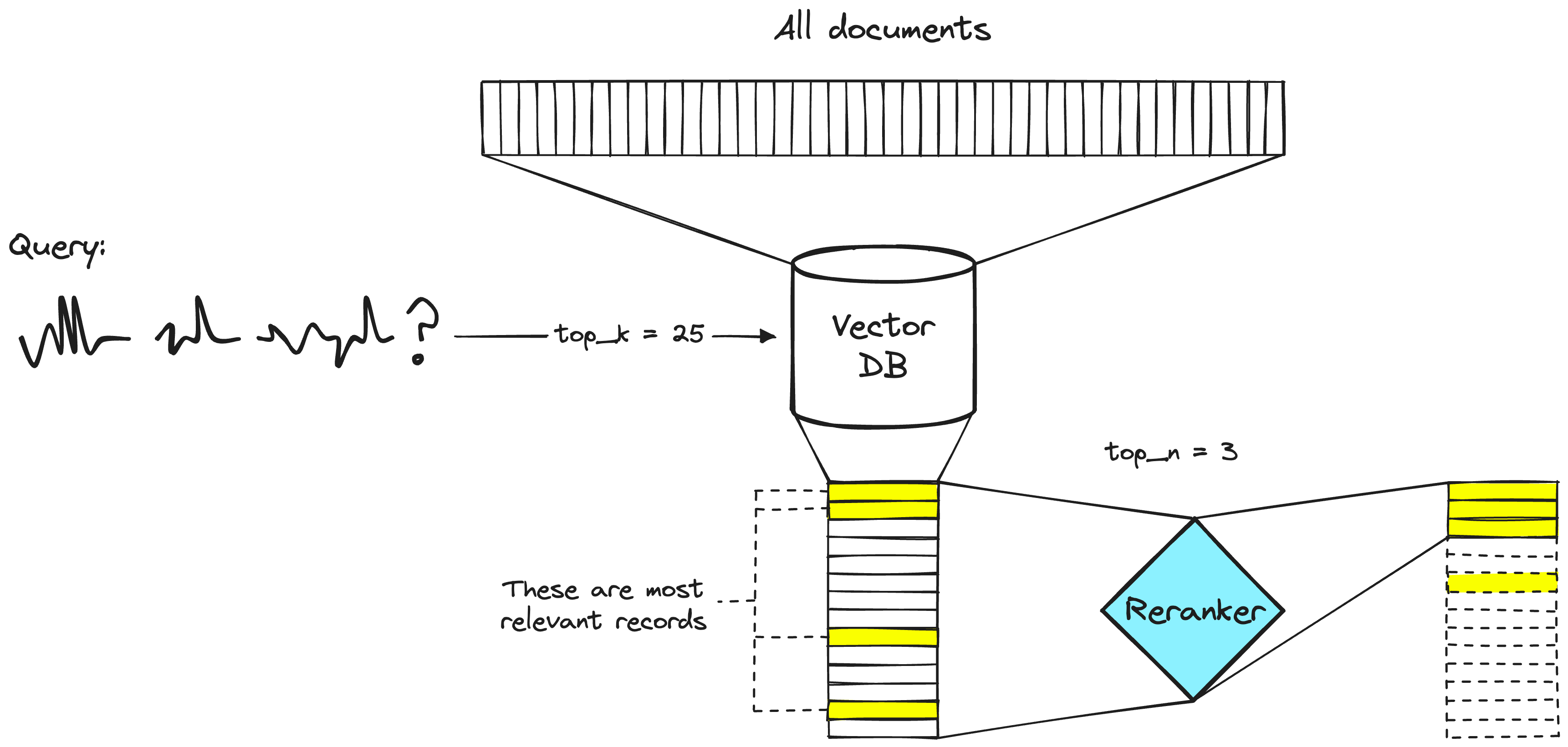
A common reranking model is the cross encoder:
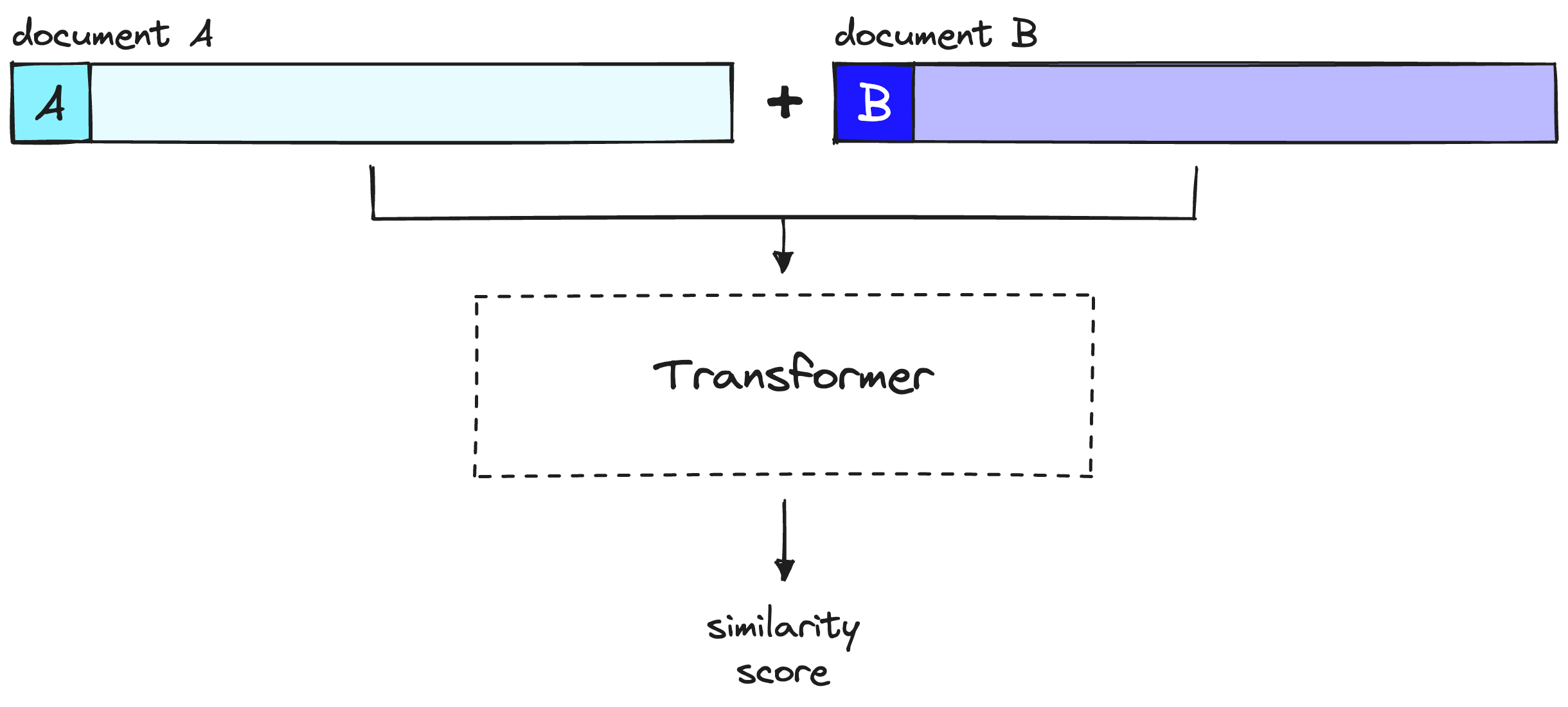
We plug this reranking model into the rag pipeline...